Recent advancements in Technology has shown us the incredible capabilities hidden inside of a machine, if it is fed properly. One such feed is the combination of Reinforcement Learning algorithms with Deep learning.
Assumptions:
- The reader is familiar with basic Q-Learning algorithm. If not, start here
- Familiarity with Deep learning and neural networks. If not, start here
- Familiarity with Epsilon-greedy method. If not, start here
In this article, you will see how Deep-Q-Learning algorithm can be implemented in Pytorch.
Yes, we are discussing Deep-Q-Learning (paper), a learning algorithm from Deep mind which involves Q-learning and Deep learning. Let’s start
Contents:
- Need for Deep-Q-Learning
- Theory behind Deep-Q-Learning
- Algorithm
- Implementation in Pytorch
- Improvements
- Results
Need for Deep-Q-Learning
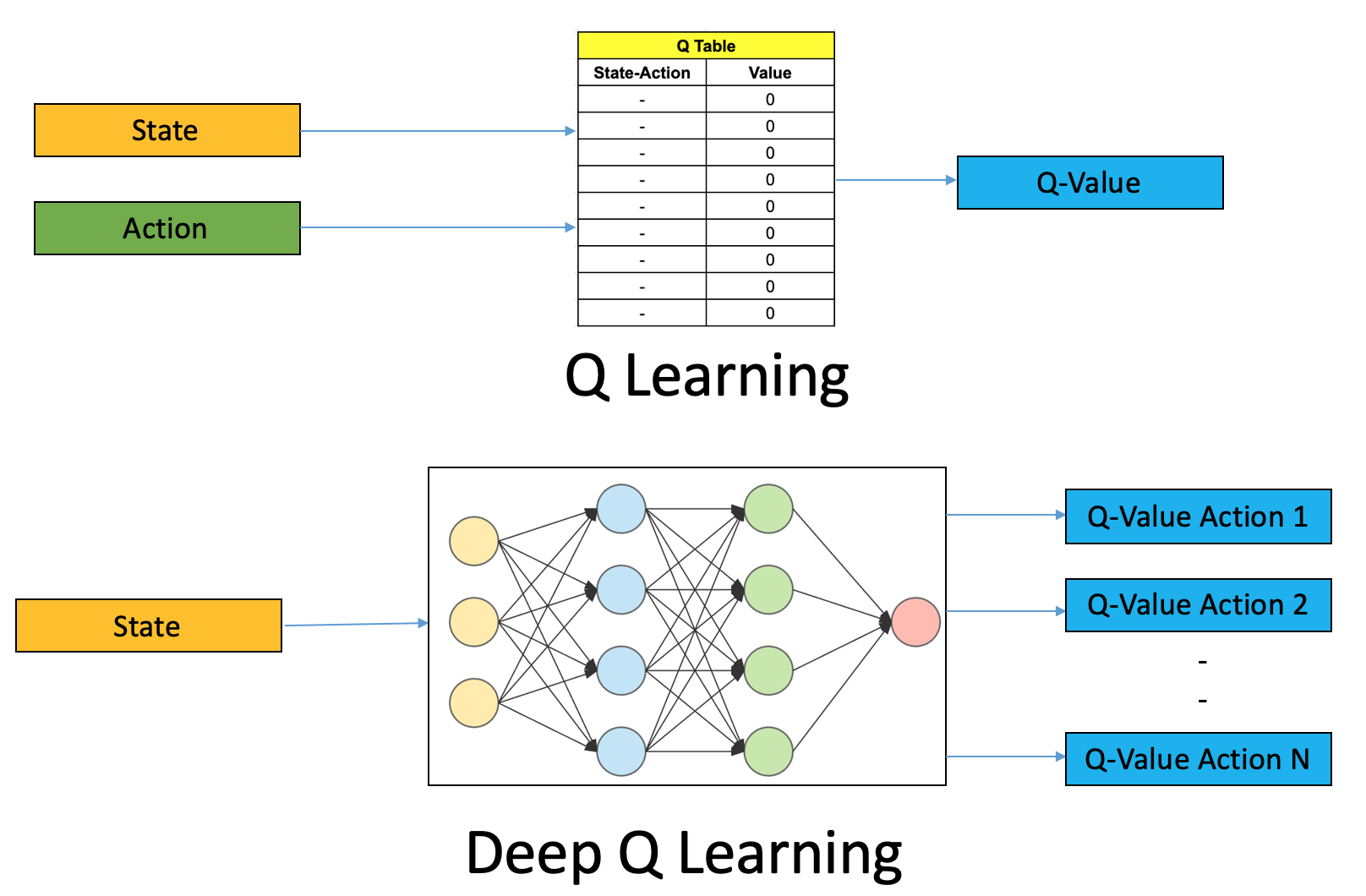
Picture credits: Analytics Vidya
In an RL environment, for state(S) and action(A) there will be a Q-value associated which is, let’s say, is maintained in a table.
But when the number of possible states are huge, for example in a computer game, Q-values associated with these state-action pairs explode in number. For this reason researchers replaced this Q-table with a function. One of the functions we will discuss today is Deep Neural Network. Hence the name Deep-Q-Learning
Theory behind Deep-Q-Learning
First let us discuss the algorithm proposed in the original paper, then we will go ahead and implement that in Pytorch
Algorithm:
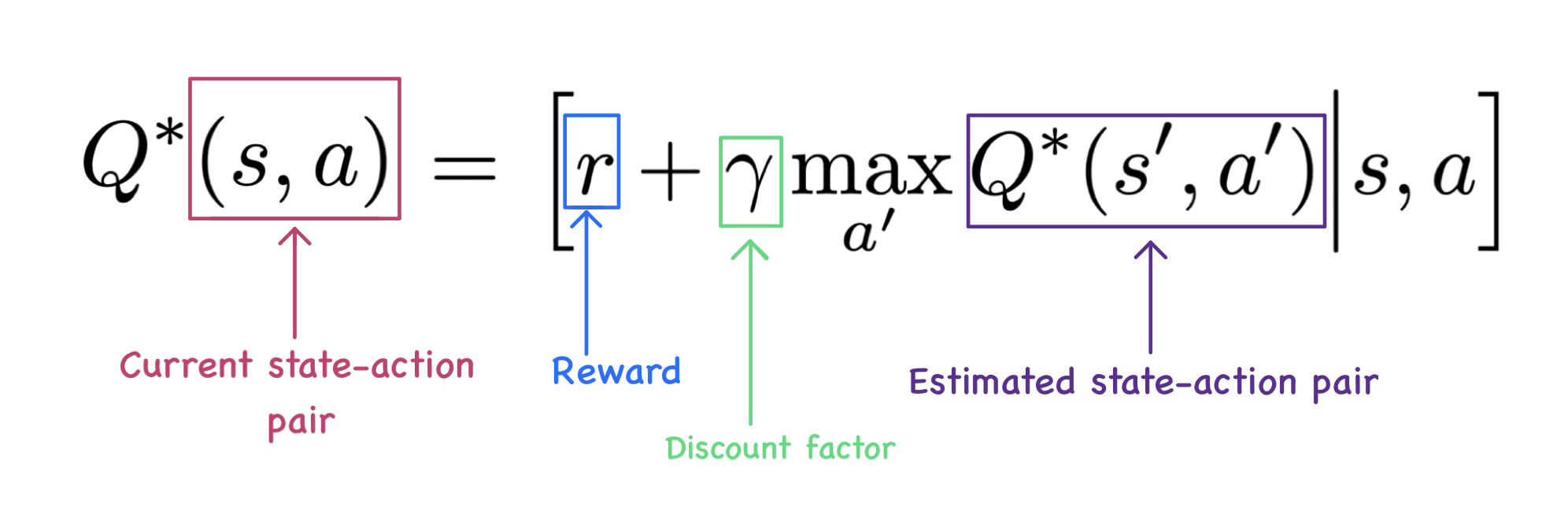 Let us understand this equation part by part.
Let us understand this equation part by part.
- Current state-action pair: A state obtained through the atari simulation.
- Reward: The reward obtained by taking action A from state S.
- Discount factor: Used to play around with short sighted and long sighted reward.
- Estimated state-action pair: From state S we transform to state S' by taking action A. Now A' is the most probable action(max) that can be taken from S'.
Implementation:
- Initialise the breakout environment: We will be using
BreakoutNoFrameskip-v4
env = Environment('BreakoutNoFrameskip-v4', args, atari_wrapper=True, test=True)
- We need to create 2 Convolutional Neural Networks. One for
Q(S,A), let’s call this Q-network, other forQ(S', A'), let’s call this target network - Using the environment, we collect State(S), Action(A), Reward, Next State(S') like we do in Q-learning.
state = env.reset() # Start with random state action = q_network(state).get_action_using_epsilon_greedy_method() # Use the q_network and then the epsilon greedy method to get the action for state S next_state, reward, terminal, _ = env.step(action) # Use generated action to collect reward(R) and next state(S')
- Now we have collected all the values required to calculate the new Q value.
# Use Q-network to get action(A) using state(S) # Q-Network is the agent we are training. We expect this network to return us q_values that helps us take right action q_value = q_network(state) q_value = q_value[action] # This is the network we use to estimate the state-action pair. target_value = target_network(next_state).max() updated_target_value = reward + (discount_factor * target_value * (1-terminal))
- Once we have calculated the target, it will act as a label to our Q-network. We go ahead and calculate the loss and run the optimiser
loss = huber_loss(q_value, updated_target_value)
Few questions need to be answered here:
- Why do we need two networks? Here, we use our Q-network for training. That means the parameters of this network keeps changing. If we use this network for estimation of state-action pair (S’,A’), then our network generates new (S’,A’) for same state(S) and will never converge. To deal with this the paper introduces a replica of our Q-network, here, termed as target network which is updated on a periodic interval, thus helping the Q-network learn in a stable environment
- Need for Replay Memory (Buffer)
The current training process discussed in the article has a flaw. If we use the atari’s environment every time to generate new state values based on actions, we end up in a sequential state set. This will limit the network’s ability to learn randomness and generalise. Hence we stored a certain number of (state, action, reward, next state) tuples in memory. We then draw a random set of tuples and train our Q-network. This ensures randomness and robustness of our network. Please refer complete codebase(check end of article for github link) for implementation details
Improvements
Few techniques on top of Deep-Q-Networks which boost the performance of our agent.
- Double Deep-Q-Networks.
- Dueling Deep-Q-Networks.
- Prioritised Replay Buffer.
Let us discuss these techniques in the tutorials to come!
Results
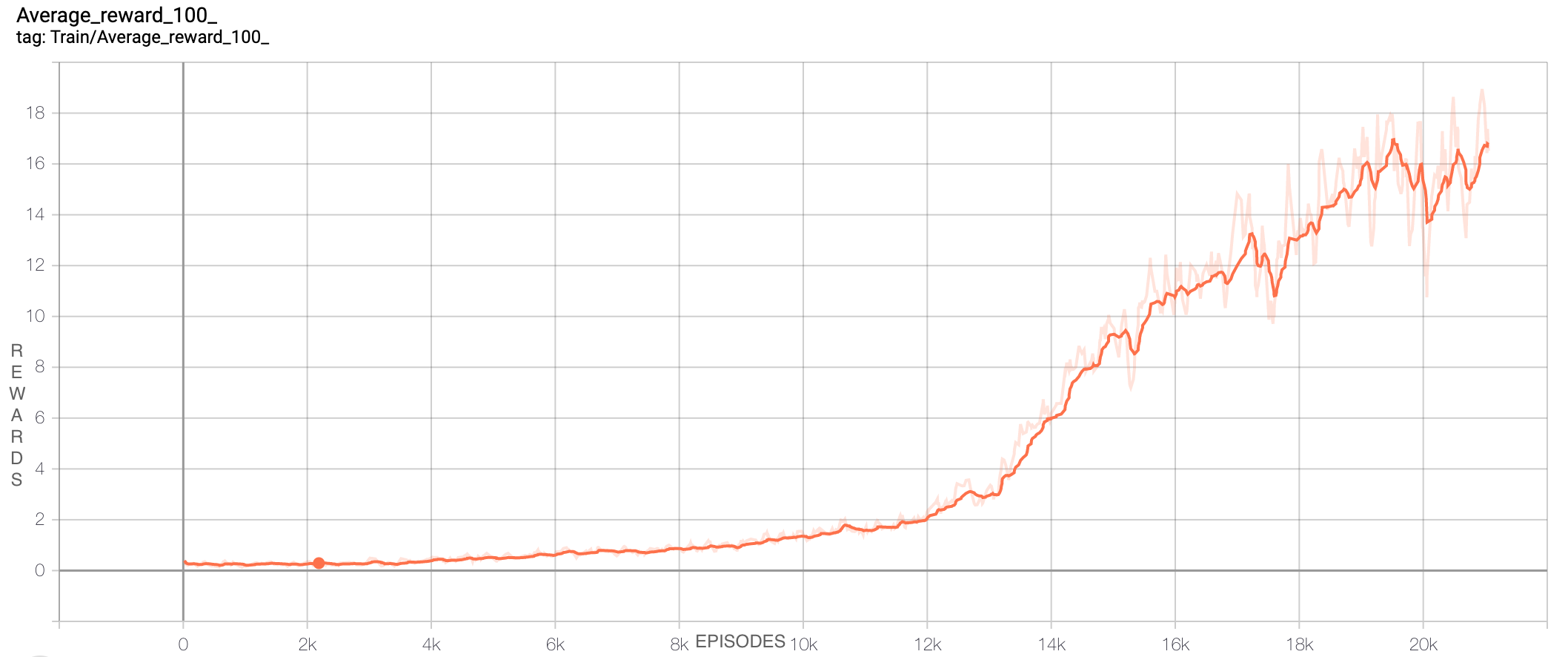
Training the Deep-network for 20k episodes -> received an average reward close to 20.
 I hope this tutorial was helpful. You can find the full codebase here.
Happy learning. Cheers !!
I hope this tutorial was helpful. You can find the full codebase here.
Happy learning. Cheers !!